
How to find information on the Web
For the most essential question a Net surfer may ask, there is more than one answer. Formulating a query to a search engine is not the only. Let me detail all the ways to find information on the Web, while knowing that webmasters on their side do their utmost to ensure that the information they provide is most likely to be found by those interested.
Search engines

Finding a sentence in a text among 10 billions pages indexed, that is possible
with main search engines, Google, Bing, Yahoo, it is enough to put the sentence
between quotation marks in a request! Most often the search is done on a list
of keywords that one provides, according to a simplistic boolean search: +
for a combination, - for an exclusion. The AND and OR operators are used in
advanced search.
Google can return pages which do not contain the required words: these words
are in fact in the links which point on the page, that is thus in relation
to the request actually.
Artificial Intelligence
It's now easy to have a program as a conversation partner, and its knowledge is vast. Windows 11 offers Copilot in the taskbar, making it particularly easy to access.
There's an equivalent on Android with Gemini. Other virtual conversation partners are also available, such as Perplexity.
To the question "Who uses the Scriptol language?", Copilot provides an accurate and very detailed answer, better than I could have provided myself, even though I'm familiar with the topic.
However, it offers code examples, and this time, the programming language is unknown to me!
We shouldn't blindly trust what AI says; information must be verified with reliable sources!
Sites of questions
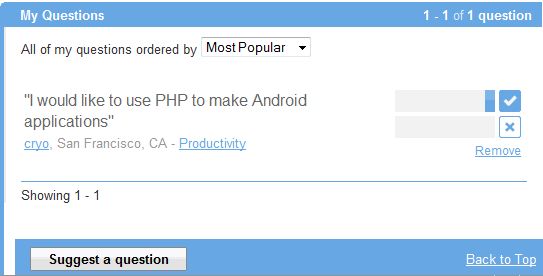
To have an answer, why not ask directly the question? On these sites, there are not robots but voluntary human that will answer the question and the sites select the best answer, that is voted by plebiscite by users. They never misses volunteers to answer, as they find a profit in various ways there. That can be the opportunity to give the URL of their own site sometimes.
Moderator was an internal tool at Google that the company decided to share with people to helps promote questions on the Web.The site was used as a first step by the company to communicate with webmasters, then lost interest to the tool and focused on Google+ it wants to promote with all kinds of services to users.
It can be very useful to webmasters, in fact, by crawling questions in various themes you know what's most interesting to people, what they would find answers. Something more explicit than the popularity of keywords. Therefore a means to guide the webmaster in developing the content of a site.
There were two ways to participate in this social site:
- Vote for a question submitted by a visitor.
- Ask yourself a question on the site.
A simple interface allows voting: give a point by clicking on the symbol "selected" or say that you do not like the question by clicking on the cross. The left field is a progress bar on the number of votes, which appears in clear when you move the mouse over.
This service can run on App Engine as a social network Web service, if you want to create your own version. But Google no longer provides an API to this software, so you have to turn to an equivalent open source project. Question2answers is precisely this, it runs already on many sites, open or private. Actually the tool is well suited to a company or a group to put forward the questions people are asking.
You can also find services close enough in StackOverflow, specializing in programming, and StackExchange more general.
Yahoo answers provides answers made by volunteers for frequently asked questions. But Answertips service would return a better result. For example, if one types "How to find information on the Web?", one obtains no answer! And one is redirected on the traditional engine using keywords.
Answers.com seems to use a traditional search engine with only 4 million page (against 1000 billion of URLs for Google), but it provides a software that allows to start a search when one clicks on a word in a page.
Quora is newer and requires that registering to access the site. Its use is less easy but the relevance can be higher than that of Answers.
For a precise question, information, something which requires an experiment, forums bring an unequaled richness. Search engines include the contents of forums, also direct access to the forums is a supplement when engines are not able to associate the question to an answer.
News and bookmarks sites
The principle of digg-likes, is to associate a score to each article. These
are the visitors by clicking on an image who give the marks to denote their
interest for the post, and thus lead attention from other visitors.
They are thus named because Digg has popularized the idea that contributed
to its fortune, and then lot of other website followed.
CMS such as Wordpress allowed any webmaster to build sites easily, and it was actually created almost a new one every day until 2011 when the Panda update which penalizes sites without original content puts an end to this trend ! Since most of these sites have been closed.
Another idea is to share bookmark with Net surfers. Rather than to keep his
list of favorites on the browser, one manages it on Delicious, Stumpleupon,
the others have access there and can discover sites as you can yourself benefit
of sites discovered by others. A relational network is created, you appreciate
what mark another Net surfer, you add it to your list of friends. Twitter and Facebook have gradually replaced these sites.
Replacing queries by association of ideas
It is sometimes difficult to find information on search engines even when we know it exists, because we can not formulate a query so that guide the engine on what we want. In this case, other sites can help.

Future of search engines

How to find royalty-free images